






Is boyer_moore_horspool faster then std::string::find?
published at 23.03.2023 15:43 by Jens Weller
Save to Instapaper Pocket
On Wednesday I've read an interesting blog post by Julien Jorge on Effortful Performance Improvements, where it is shown how to improve an replace function which runs replacements on a string. Its part of a series on performance and improving a code base, you should go read all of them!
When reading the post, and seeing the two implementations, one short and simple and the other longer and more complicated - but faster - I wondered is there a faster way? Julien already has shown that his newer function beats his old function which uses std::string::find in performance. I've veryfied that, and then started to refactor a copy of that slower function with a different approach using the string search algorithm boyer_moore_horspool. So there is no comparison between that first implementation with std::string::find and the newer one. Mostly as it would make the tests run longer and its going to come in 3rd place mostly anyways.
A while ago I blogged about searching and replacing in strings with boost. This functionality is now also available in the standard since C++17, and as the patterns searched for in Juliens blog post are of longer strings it made me wonder: would a string searcher be faster here? Which is likely depending on your context where such a function runs, like the length of the haystack and the needle. A longer needle should perform better. But then there is also modern processors, cache friendliness and that a function like string::find might already be optimized in a better way.
So I set out to write a short replace_search function using the standard std::boyer_moore_horspool_searcher with std::search:
void replace_search(std::string& s,const std::boyer_moore_horspool_searcher< const char*>& bms,size_t from, std::string_view to)
{
auto it = s.begin();
while (it != s.end())
{
it = std::search(it,s.end(),bms);
if(it != s.begin())
s.replace(it - s.begin(), from, to);
}
}
And the benchmarking code running this
static void StringReplace(benchmark::State& state) {
std::string s("Hello ${name}, test text is ${test}, ${num},${num},more text");
// Code inside this loop is measured repeatedly
std::string_view name("${name}"),test("${test}"),num("${num}");
std::boyer_moore_horspool_searcher bmsname(name.begin(),name.end());
std::boyer_moore_horspool_searcher bmstest(test.begin(),test.end());
std::boyer_moore_horspool_searcher bmsnum(num.begin(),num.end());
for (auto _ : state) {
std::string copy(s);
replace_search(copy, bmsname,name.size(), "Michael");
replace_search(copy, bmstest,test.size(), "pass");
replace_search(copy, bmsnum,num.size(), "42");
// Make sure the variable is not optimized away by compiler
benchmark::DoNotOptimize(copy);
benchmark::DoNotOptimize(name);
benchmark::DoNotOptimize(bmsname);
benchmark::DoNotOptimize(test);
benchmark::DoNotOptimize(bmstest);
benchmark::DoNotOptimize(num);
benchmark::DoNotOptimize(bmsnum);
}
}
// Register the function as a benchmark
BENCHMARK(StringReplace);
And in this setting, it is faster.
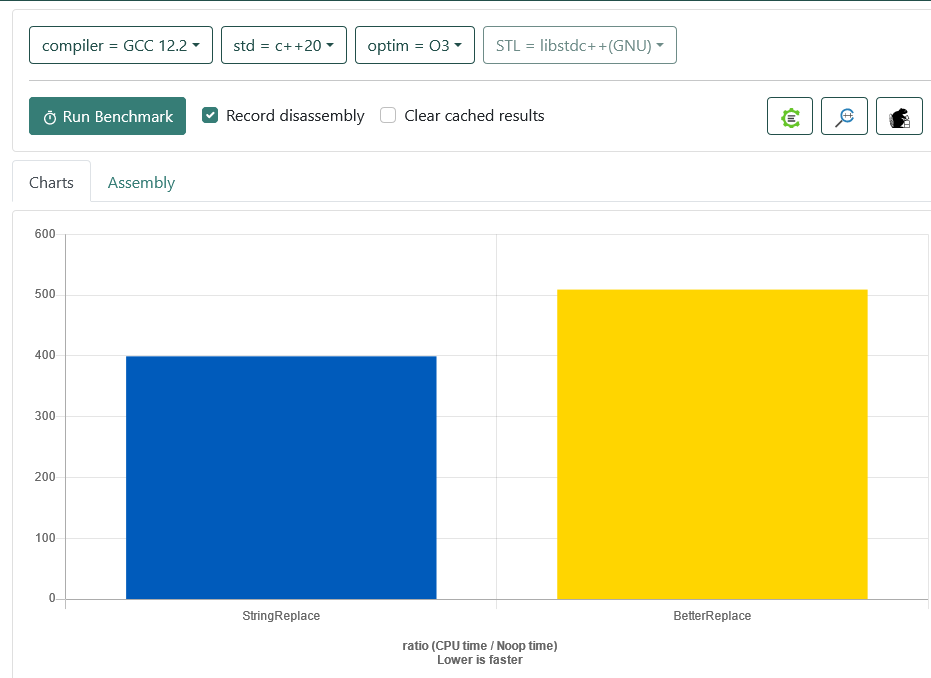
Though if you'd need to build the searchers for each function invocation, this would not be the case. Also this is influenced by the length of the search string, and the length of the patterns you are looking for.
I'm wondering if an even faster version could be build that like the version in the blog post, does all replacements at once. One idea in my mind is to simlpy have a vector of string_views, that contains the parts between the patterns and the replacement for the patterns. Then one would just have to allocate a string of the size of all string_views and copy them into it. Full code on godbolt.
So is the boyer_moore_horspool_searcher faster then std::string::find?
As the code shows, it can be faster. But it has its own constrains, and only if they can be met in the context of the code, then this method is faster. One of the core variables here is the length of the pattern searched and the length of the string it self. Also replacing the original string might not be the best strategy. Likely there are still a few allocations one could avoid in this. Its also a good question to ask what are the bottlenecks of the solution Julien presented and std::string::find it self. A vectorized approach might be even faster then the solutions seen so far. One thing I'm not sure with is, if this actually can be applied to Juliens code base, if each invocation of the function brings its own set of search patterns, it could be too much overhead to manage this to actually be faster.
I've been thinking about string parsing in the last weeks too, so this was a great opportunity to play around with the string searchers. And like so many tools in C++, they are great to know about, but often not the right tool. The overhead in construction of the searcher means, that you'll mostly benefit in situations where this is used in a cached way. A map of searchers for patterns could be in some use cases helping with not having to rebuild the searchers for each invocation. So this function using searchers could turn into a class, which then stores the searchers for reuse.
Join the Meeting C++ patreon community!
This and other posts on Meeting C++ are enabled by my supporters on patreon!